一致性模型(Consistency Model)小结
0 引言
随着分布式数据库的普及,一致性模型(Consistency Model)这个原本只在系统领域研究人员这个小圈子中传播的概念的知名度也越来越高。 然而,由于这一概念相对来说本身就比较复杂,而且不同的小圈子(e.g., 单机多线程,分布式系统,数据库)使用的术语又总是有那么些微妙的差别,最终的结果就基本是一团浆糊。 就连向来备受信任的维基百科也不得不在其关于 Consistency Model 的页面上标注特别的声明,以提醒说 “This article may be confusing or unclear to readers”。 因此,作为我个人的一个总结,本文将列举据我所知最常见的几种一致性模型的定义以及它们之间的区别(总体来说本文的内容主要由这篇英文博客的翻译和一系列私货组成)。 若有什么不当之处望请通过邮件向我提出,我会尽快予以修正。
1 什么是一致性模型
由于传播途径的原因,一致性这个概念最常见的定义是“同一数据的多个副本之间是否保持一致”。 在描述上这个定义容易让人产生两个不必要的误解: 一是可能会有人误以为只有在不同机器上存在多个副本时才会产生一致性问题; 二则是它忽略了由于没能保证数据操作的原子性而导致的数据不一致(经典的银行转账的例子想必不用我特意来复述)。 这里我无意去细究这些文字上的问题,因此我打算用“顺序”这一更加明确的概念来进行重新的定义,即一致性模型规定的是“我们能够明确地区分哪些操作的先后顺序”。
形式化地来说,我们想象一个支持特定种类操作的数据结构,那么这个数据结构的一致性模型就定义了对其进行并发访问时各操作最终生效顺序上的约束。 如果你进行过多线程或者分布式的编程的话,想必你一定能够理解上文中提到的“最终生效”的顺序经常并不等价于各个操作的时间顺序(比如说在几乎同一时间对一个 Concurrent Queue 并发执行两次 Push 操作的话,其结果并不一定按照这两个 Push 操作的开始或结束时间存放)。 另外需要注意的是,这里我们不关心数据结构内部的状态,仅仅讨论由操作的返回值所观测到的结果。 在这一语境下我们能够定义得到的最简单的一致性模型为无一致(No Consistency),即不保证任何一致性。 它的意思是每一次操作的返回结果都是未定义的,可以返回任意的结果。 使得这一情况出现的最常见原因是未能够保证操作的原子性(thread-unsafe)导致了数据结构内部的不一致,不过这已经属于软件错误的范畴内了,因此本文不与进行进一步地讨论。 相对的,常见的一致性模型都至少保证 arranged correctly,即我们可以找到至少一个特定的顺序 $\mathcal{o}$,使得这些并发操作的结果与将它们依次按照 $\mathcal{o}$ 所规定的顺序在单线程上执行相同。 在这一条件下,一致性模型其实就是定义了 $\mathcal{o}$ 所能选择的一个范围。 换句话说,如果并发执行了 $N$ 个操作,那么理论上就有 $N!$ 种可能的顺序,而一致性模型就是定义了由这 $N!$ 种顺序构成的全集中的一个子集 $\mathcal{O}$,并规定 $\mathcal{o} \in \mathcal{O}$。
熟悉数据库系统的读者可能立即就会发现,上述定义中一致性的概念相对于所谓 ACID 特性中的 C 更加类似于 I 的定义。 这也就是为什么我在引言中会特意提到各领域间术语意义不一致的来由之一。 更进一步的,虽说在单机多线程和分布式环境下常说的一致性都是采用的上述的这个定义,它们常用的术语还是有些微妙的区别。 因此,本文随后将首先讨论单机多线程环境下常见的几种一致性模型,因为它们有着较为严格的形式化定义。 其它模型则会在最后分别进行讨论。
2 单机多线程环境下的一致性模型
2.1 强一致(Strong Consistency)
强一致模型有时也被称之为可线性化(Linearizability),是单机多线程环境下常见一致性模型中最强的一类(即 $|\mathcal{O}|$ 最小的一类)。 他要求任意两个在时间上不重合的操作(无论这两个操作是否在不同的线程中执行)都能够被区分顺序。 借用这篇博客中的图示来说明的话, 每一个操作都被表示为一条线段,不同的轨道表示不同的线程,而横轴为时间顺序。 如果这一数据结构是满足强一致的那么操作 x 对其的修改对于所有在 x 结束时间之后才开始的操作都是可见的。 相对的,如果另一个操作 y 的执行时间与 x 有重合(如图中红色的那些操作),那么 x 与 y 的生效顺序是任意的。
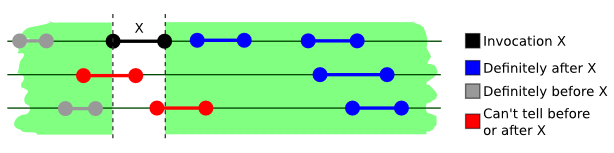
按照定义强一致模型是可组合的。也就是说如果一个操作由两个满足强一致的子操作组成,那么父操作也是强一致的。 强一致提供了一系列很好的特性,也非常的易于理解,但问题在于它基本很难得到高效的实现。 因此,研究人员就将其进一步的放松,从而得到了在单机多线程环境下实际上普遍存在的顺序一致性。
2.2 顺序一致(Sequential Consistency)
我们可以很容易地想到,强一致之所以难以高效实现的原因在于它对由不同线程执行的操作间的顺序都作出了限制,因此需要一个全局同步的时钟。 相对的,顺序一致模型(也被称之为可序列化)就只要求能够区分同一线程中各个操作的顺序。 用同上的图例的话,就会得到下图所示的结果。 从中我们可以看到,只要两个操作的执行线程是不同的,那么它们最终的生效顺序就是任意的。
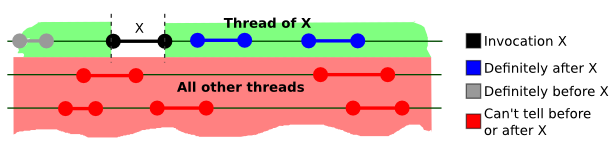
虽然看上起顺序一致已经对约束进行了极大地放松,但事实上还是不够的,甚至可以说我们现在常用的各种编程语言其实都是不支持完整的顺序一致的。 这主要是因为现在的 CPU 和编译器会尝试对代码进行各种各样的优化,有时候它们可能会为了优化性能而把程序员在写程序时规定的代码执行顺序打乱,从而导致程序不满足顺序一致的结果。 举一个很简单的例子,假设 x 和 y 这两个变量的初始值都为 0,而两个线程分别执行以下的程序:
| Thread 1 | Thread 2 |
|---|---|
| x := 1; | y := 1; |
| res1 := y; | res2 := x; |
在满足顺序一致的情况下,上述的程序最终是绝对不会出现 res1 和 res2 的值都等于 0 的情况(其他三种都是可能的)。 但为了得到更好的效率,编译器有可能在不清楚 x 和 y 是共享变量的情况下隐式的将 Thread 2 的两条指令的顺序颠倒(常见的原因包括向两条数据依赖的指令间插入一些其它指令以防指令流水被打断等)。 在这种情况下只要程序是按照 Thread 2 -> Thread 1 -> Thread 1 -> Thread 2 的顺序执行,就会产生 res1 和 res2 的值都等于 0 这种不满足顺序一致的结果。 因此,为了在效率和一致性之间进行 tradeoff,现有的编程语言(如 C++)一般只提供 “sequential consistency for data race free programs”。 也就是说,只有当所有的共享内存变量都有相应的同步原语进行保护(即没有 data race)时,程序的顺序一致才得到保证。
P.S. 顺序一致并不满足上面提到的可组合性,由多个顺序一致的操作组成的父操作并不一定满足顺序一致。
2.3 静态一致(Quiescent Consistency)
虽然顺序一致在实现效率上较之强一致优势非常明显,但其完全不对不同线程间操作进行限制的特性有时也会使得只支持顺序一致的数据结构变得难以使用。 因此 Maurice Herlihy 和 Nir Shavit 等人提出了静态一致的概念,它保证如果两个分属不同线程的操作间有一段完全空闲的时间,那么这两个操作的顺序是可以被区分的。 图形化的表示的话就是下面这种感觉:
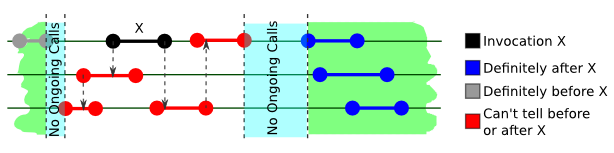
需要注意的是,被称之为 Quiescent 的这一段时间是要求完全空闲的,即没有任何一个线程有执行操作。 得益于这个条件,静态一致同样是可组合的。 虽然看上去很奇怪,有很多的 Concurrent Data Structure 提供的就是静态一致的模型,具体的话可以参考这篇文章。
3 其它一致性模型
3.1 最终一致 (Eventual Consistency)
在分布式环境下,由于不同计算单元间进行通讯的开销远大于单机多线程的情况,即便是上述的简化版顺序一致依然是难以达成的。 因此,考虑到在很多实际的例子中用户其实并不要求他们的操作立即生效,研究人员就提出了最终一致的概念。 在定义上,最终一致只要求当两个操作间的间隔时间足够长时保证它们之间的顺序。 然而事实上这个定义并不比没有高出多少,因为其并不定义隔了多长就可以称之为“足够长”了。 简单地来说最终一致性可以算得上是一个下限,他基本上就是“为了 IOPS 我已经什么都不管了,总是最后总是会有效的,你也就别要求那么多了”的代名词。
3.2 严格一致 (Strict Consistency)
总体来说严格一致的定义和 2.1 中提到的强一致是很类似的,不过它只针对 read 和 write 这两个原子的操作。 其要求所有的 write 都立即有效,即所有发生在这个 write 的结束时间点之后的 read 都能读到这个 write 所写的值。
3.3 释放一致 (Release Consistency)
与严格一致类似,释放一致性也只是针对两个特殊的操作 acquire 和 release(可以类比于加锁和解锁)。 它要求所有所有对共享变量的修改操作都必须包含在一对 acquire 和 release 中。 在这一条件下,它就保证如果一个计算单元成功进行了 acquire,那么在这之前所有已经执行完 release 了的操作都是可见的。 (基本上类似于前面提到的 sequential consistency for data race free programs)。