May 15, 2016
说实话我一直觉得这一类 google 一下就能得到答案的所谓 “常见面试题” 并不是一个很合适的考察方法。
作为一个码农,比起死记硬背的能力来说通过使用 google 等工具短时间内搞明白一件事情的能力显然更为重要。
所以作为简单地问问题的替代,我觉得其实可以给一个相对来说比较复杂的问题外加一台内置 VPN 的电脑,然后要求被面试者在一定时间之内尽可能的调查清楚这个问题并回答。
当然了,由于这个世界上的事情经常是无法如意的,所以该准备的还是要准备 ......
1. 没完没了的虚函数
虚函数的意义和实现方法基本上算是必考题了,不过鉴于其在实际工程中的确非常常用,这样的考察频率倒也无可厚非。
这里我不打算详细介绍那些随手 google 一下就能出来一大堆的内容,只是记录一下几个比较容易不小心搞混的地方:
- 对于有虚函数的类,其每个实例都各自有一个隐式定义的 vptr;相对的,vptr 指向的 vtable 是每一个类一个的。
- 因为虚函数的调用有指针的跳转,并且无法应用诸如 inline 等一系列优化技巧,虚函数的调用开销一般比普通函数要大。
- 由于基类在初始化时无法找到子类的虚函数表,所以 constructor 不能是虚函数;相对的,为了避免 delete 一个由基类指针指向的子类实例时可能的内存泄漏,destructor 要求必须为虚函数1。
- 由于 static_cast 是直接进行数值之间的转换,所以如果用它做在基类和派生类之间转换的话需要程序员自己保证这个转换一定是合法的;相对的,dynamic_cast 可以识别出不合法的转换并返回 null,这是因为 vtable 中保存了类的 RTTI (Run Time Type Info)信息2。
2. 永无止境的 C++
除了上面提到的虚函数外,C++ 还有很多神奇的特性,多到一般人根本不可能 “精通” 的程度。
因此这里我也就是列举一下比较常见的几个问题。
2.1 malloc V.S. new V.S. placement new
C 的 malloc 函数与 C++ 的 new 操作符最大的区别就在于前者是 type ignorant 的,它只是分配特定大小的区域(并将大小信息记录在尾端3)然后返回指向它的 void* 指针而已。
理论上来说 malloc 返回的区域中的值是随机的。
相对的,new 不仅仅会分配一块内存,还会调用对应类的构造函数,从而完成类的初始化。
另外,malloc 的失败是通过返回值返回的,new 则是抛出一个 std::bad_alloc 异常。
与上面两个不同,C++ 还提供 placement new,其功能是在给定的内存缓冲上构造一个实例4。
也就是说 placement new 本身不分配空间,只是调用相应的构造函数。
与 Boost.Pool 相互配合的话就可以实现一个简单的自定义内存分配方案。
2.2 ELF 程序的运行空间
程序的运行空间可以被分为 BSS(Block Started by Symbol)段、数据段、代码段、堆、与栈等五个部分。
后三者大家都表熟悉,相对的 BSS 和数据段都是放置全局变量的,只不过 BSS 被用来存放程序中未初始化的全局变量,因此是可写的(在程序执行之前 BSS 段会自动清 零);而数据段都是些已初始化的常量什么的,因此是只读的5。
2.3 static 关键字
static 这个关键字被用在不同地方的时候意义各不相同。
- 比如说如果被用在全局变量/普通函数前面的话就定义了一个全局静态变量/静态函数。这种变量/函数的好处在于它的作用域仅为声明它的文件,因此可以在不同文件中定义同一个名字的全局静态变量而不互相冲突。
- 上述静态函数最常用的一个例子为放在 .h 文件里的 static inline 函数,如果没有这个 static 的话每个 .cpp 文件里都会有一份一样的函数,从而造成冲突。
- 局部静态变量更像是全局静态变量的一个语法糖一样的存在,只不过编译器会自动添加检查语句来将它的初始化延迟到对应函数的第一次调用时6。
需要注意的是,一般的函数局部变量是放在栈上的,而局部静态变量是在 BSS 里的。
- 静态成员函数和静态成员变量过于常用,因此这里就不赘述了。
2.4 RAII
RAII(Resource Acquisition Is Initialization)其实应该算是一种设计模式。
它的意思就是将资源的获取与释放分别放在一个类的构造和析构函数里。
这样就可以利用 C++ 自身的作用域管理而不是手动的对资源进行管理,避免泄漏。
常见的一种目的就在于避免由于程序运行的中间抛出了异常导致放置在程序末尾的释放语句没有被执行7。
关于 C++ 还有很多其他问题,比如智能指针的实现方法8什么的,不过它们大多都被问烂了,因此这里也就不列举了。
3. 杂七杂八的各种问题
3.1 select V.S. epoll V.S. kqueue
select 的主要缺点有两个:一个是它只返回有数据了而不返回具体是哪一个 socket,因此需要线性的遍历一遍;另一个则是它只支持 1024 个 socket(因为它采用 32 个32位整数的比特位表示 socket),需要增加的话要修改 FD_SETSIZE。
相对的 epoll 维护了特殊的数据结构,可以直接返回哪一个 socket 状态变化了。
kqueue 就是 BSD 上的 epoll,不过在某种意义上效率更好一点9。
不过说实话我觉得在 ZeroMQ,libevent,DPDK 等不同层面的网络库存在的情况下,直接用上面那几个基础接口编程实在是一件费力不讨好的事情 ......
3.2 HTTP GET V.S. HTTP POST
偶然看到的一个问题。
似乎按照 HTTP 的规范 HTTP GET 只能是用于获取信息而非修改信息,因此必须是幂等的(即多次请求结果应该和一次一样)10。
3.3 单例的 X 种实现方式
说实话我觉得设计模式最大的问题就在于它定义了一大堆其实并没有必要的专有名词,而且这些名词还都没有一个形式化的明确定义,从而导致不同的地方意思还总是不太一样。
当然还有就是那些奇怪的 JAVA 代码,实在是不好理解。
不过常见的几种设计模式的思想和实现方法其实还是很有意思的。
拿最常见的单例模式举例的话:
如果简单的用 static 成员变量来实现的话就会在镜像装载的那一刻初始化,因此也被称之为 “饿汉”;
相对的,如果在第一次真正使用时才初始化的话就被称之为 “懒汉”;
同时,由于懒汉方式在多线程环境下有数据竞争的问题,还发明了能够减少同步次数,用 Double-Checked Locking 优化的线程安全版懒汉11。
总的来说这些实现方式都去了解一下的话还是挺有意思的。
其他的设计模式中我个人觉得最好玩的是 Command。它的意思是将两个类 A,B 间的直接调用拆解为 A 产生一个 Command 类的实例,而 B 则执行一个参数为 Command 的函数。通过 Command 类 A 和 B 之间的紧耦合关系被解耦了,因此如果调用的参数发生变化了修改起来很方便,A 和 B 各自替换起来也很方便12。
当然其他的比如 Observer 和 Flyweight 也很有用,只不过有的时候总有一种不需要这么严格的定义,其实照着思想直接自己设计还更方便的感觉。
Click to read
May 12, 2016
说明:本文所用图片部分来源于网络,但出处已然不明。如有不妥之处,望请通过邮件与我联系。
0 从数据并行到图并行
自从 04 年 Google 公开了它的 MapReduce 之后,大家就像是发现了什么新大陆一样以极大的热情投入到新型计算框架的研发以及已有框架的优化之中。
如果要说这一系列的工作有什么共同点的话,那就是它们都致力于提供一个简单易用的上层接口,从而将底层的诸如二级存储访问、网络通讯、横向扩展、单点容错等相对来说更复杂的问题透明化,达到普通的软件开发人员只需要聚焦于上层应用的目的。
然而,在应该选择什么样的接口,以及采用何种的底层架构对它进行实现这些问题上,目前仍然处于一个众说纷纭的阶段。
虽然 Spark 系列框架致力于以 RDD 为基础一统天下的愿景值得赞叹,但由于效率上的问题,目前的主流观点仍然认为应该针对数据并行计算、图计算、流计算、和矩阵计算等不同类别的应用分别使用不同的架构与之对应。

以本文讨论的图计算为例,由于图数据自身具有结构不规则的特点,如果简单地像 MapReduce 那样用点或边的 hash 值对其进行随机划分的话很容易造成负载的不均匀,以及极为庞大的通讯量等诸多问题。
同时,由于图算法在计算时数据局部性不好的特点,如果不进行特定的优化的话也经常会使得系统的 cache 利用率不高,从而极大地影响效率。
针对这一类的问题,许许多多的图计算框架被提出和实现,而它们又分别针对不同的更小规模的应用类型。
这一状况无疑造成了一定程度的混乱。
因此,本文将分别从“同步 V.S. 异步”,“图的划分”,“二级存储的利用”,以及“计算引擎的优化”等四个重要的 design choice 展开,并将依次讨论它们各自的发展过程。
总体来说,本系列将主要讨论下图所示的 11 篇论文。

1 一切的起源:Pregel
虽然图计算本身的历史比计算机的还要长,但如果说要找一个现代图计算框架的起源的话,由 Google 在 10 年的 SIGMOD 上公开的 Pregel 系统应该是众望所归的。
其定义的数据模型 Data Graph 和编程模型 Vertex-centric Programming 目前仍然是各个后续系统参考和借鉴的对象。
具体来说,所谓数据模型就是定义了如何将一个具体的问题表示成图的形式的方法,而在 Pregel 系统中所有处理的数据都必须要存放在一张 Data Graph 里。
虽然下图并没有明确地标示出来,Data Graph 为一张有向图,其在各个点之间的拓扑关系(Topology)的基础上还允许用户为每一个点或者边定义属性(Property)。
比如在最常见的 PageRank 算法的例子中,各个点的权值一般就是它的 PageRank 值,而边的权值则可以被忽略。

在这一数据模型的基础上,用户只需要通过 Pregel 提供的以点为中心的编程接口(Vertex-centric Programming)进行编程就可以实现各种算法,而无需考虑底层的通讯等具体实现。
一般来说,这一类的编程方法被称之为“Think as a Vertex”。
它要求用户所实现的 Vertex Program 的操作范围仅为对应点的临域(即自己的点权和所有相连的边权),而且只被允许读取入边上的值和修改出边上的值。
这些限制的主要目的在于方便并行的实现,理论上只要没有操作到共享的数据对应两个点的 Vertex Program 就可以并行地执行。
更进一步的,Pregel 的计算系统遵循所谓 Bulk Synchronous Parallell(BSP)的计算模式,即“每一次计算由一系列 superstep 组成,每一个 superstep 又可以分成本地并发计算、全局通信和同步三个步骤;在本地计算时不产生任何通讯,全局通讯时也不进行任何计算”。
这种计算模式的好处在于其非常的简单,基本不需要做任何的并发控制,同时也便于实现基于 checkpoint 的容错机制。
同时缺点就在于同步的开销大,如果负债不均衡的话很容易得到次佳的执行效率。
在 Pregel 系统中,每一个 superstep 的本地并发计算阶段就是各个节点分别执行 Vertex Program 的过程,而全局通信阶段则负责把产生的消息(附带在出边的边权上)送达相应的计算节点。
由于 Pregel 采用的是基于点的图划分方法(即将 Data Graph 中点均匀的划分给不同的机器,每个点与它所有的邻边都存储在一起),每一条被分割的边(即这条边的的两个点被分到了不同的机器上)会产生一次远程通讯。

2 同步 V.S. 异步
上述的 Pregel 系统结构十分简单并且行之有效,但仍然存在很多的问题。
其中一个就是由于 Pregel 的同步计算模式要求运算速度快的节点每一个 superstep 都必须要等待运行速度慢(或负载更高)的节点,从而造成了大量的浪费。
特别是在诸如 BFS 的一类问题中,随着计算的运行可能每一个 superstep 只有对应一部分的点的 Vertex Program 需要被执行,而且每次需要被执行的点集合都是不同的。
这一状况无疑加重了系统可能的浪费情况。
为了解决这一问题,以 GraphLab 为代表的一系列系统都支持被称之为“异步”的计算模式。
在异步模式下不存在 superstep 的概念,每一个计算节点各自维护一个调度队列包含可以被执行的点。
其保证 1)每一个点 Vertex Program 只有当其入边的值被修改了或者被显示地通知了的时候才会被执行;以及 2)如果两个点间有边相连,那么它们不会被同时并行地执行。
前者减少了不必要的开销而后者则保证了不会产生数据读写上的冲突。
在 GraphLab 中,上述的冲突控制是通过在每一个点的 Vertex Program 执行前先对所有相邻边加上锁实现的。
一般来说同步和异步的执行模式各有优劣,异步的模式可以减少负债不均衡带来的性能损失,而在负债基本均衡的情况下,同步的模式由于其更小的调度开销速度更快。
更进一步的,在特定的应用中,有可能在不同的执行阶段其最佳的执行模式也是不同的。
比如说上面提到的 BFS 的例子,在执行的初期和末期,由于需要 active 的点较少异步模式更加合适。
相对的,在 BFS 执行的中期,有可能就是同步模式的执行速度更快。
为了利用这两方的优点,上海交通大学陈海波老师组在 PPoPP '15 上发表的论文“SYNC or ASYNC: Time to Fuse for Distributed Graph-parallel Computation”就提出了一种基于预测的智能切换方法,达到了最高 73% 的加速。
3 图的划分
除了同步和异步的计算模型,在分布式环境下另外一个甚至更加重要的问题就是如何对图进行划分。
早期的 Pregel 和 GraphLab 等系统采用的都是上面提到的基于点的划分方法(Vertex-based),由于被分割的是边,有时也称之为 edge-cut(还有叫 1D partitioning 的)。
这种划分在各个点所相邻的边数比较均匀的时候是一个还算可以接受的办法,但问题在于,根据调研实际图计算中常用的图都满足 power law,即存在一定数量的点占据了绝大数量的边(如下图所示)。

在这一情况下 1D 的划分方式就很容易产生极大的负债不均衡,因此 CMU 的研究人员在 2012 年的 OSDI 上公开了 PowerGraph,其中提出了基于边的划分方法(Edge-based,vertex-cut,2D)。
简单地说,2D 的划分方法就是将图中的边(而不是点)均分给各个计算节点从而达到负载均衡的目的(因为计算开销一般是和边数成正比的)。
同时,由于那些度数非常高的点在 2D 情况下可以被划分给多个节点,它们的计算可以被并行化。
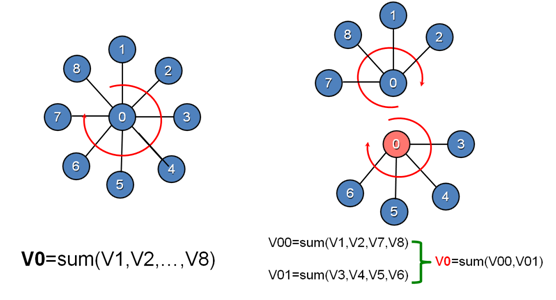
为了达到上述的目的,最原始的 Vertex Program 显然是不合适的,因为它要求一次就将与一个点相关的所有计算都完成。
因此,PowerGraph 提出了一种与 Vertex Program 类似的计算模型 GAS。
GAS 和 Vertex Program 一样都满足每个点相关的计算只访问其邻域的局部特性,但 GAS 将 Vertex Program 的过程明确地分割成了 Gather,Apply,和 Scatter 三个步骤,并通过强制要求 Gather 阶段对每一条边的结果进行聚合时的操作必须满足交换律和结合律的方式使得上图所示的并行化可以实现。
鉴于 GAS 的具体内容已经有太多等文章予以介绍,这里我就不再赘述。
如果不清楚的话建议参考这篇博客(需要注意的是,这篇博客将 PowerGraph 等价为了 GraphLab,因为事实上 PowerGraph 也被称之为 GraphLab 2.0)。
我们可以看到,PowerGraph 的 2D 划分方法最大的优点就在于它将拥有极大度数的那些 power vertex 的计算也并行化了,从而降低了可能的负债不均衡。
不过如果我们只是简单的利用边的 hash 值将它们平均的划分给各个节点的话,依然有可能产生巨大的通讯量。
具体来说,在 2D 划分方法中,如果与一个点相关的边被划分给了 X 个不同的节点,那么这个点在实际的系统中就需要维护包括一个 master 和 X-1 个 replica 在内的 X 份数据。
同时,每一次 GAS 操作时 master 都必须收集相应的 X-1 个 replica 的 partial-gather 结果并将最终计算后得到的值同步给它们。
由此可见,在 2D 划分方法下通讯量的大小是和 replica 的数量成正比的。
为了减少 replica 的数量,PowerGraph 以及随后的一些论文中都提出了各种各样的方法,然而它们经常难以在划分速度和划分结果这两个方面都达到一个很好的结果。
在此基础上,EuroSys '14 上的论文“PowerLyra: Differentiated Graph Computation and Partitioning on Skewed Graphs”提出了 hybrid-cut,其通过区分对待高度数的节点和低度数的节点达成了一个很好的结果,从而获得了那年 EuroSys 的 Best Paper Award。

从上图可以看到,hybrid-cut 的方法其实很简单,当一条边的终点度数小于阈值(上图中为 3,但一般设为 100~200)时则将这条边按其终点的 hash 分配,反之则按源点的 hash 分配。
上图中除 1 以外的所有点入度都小于阈值,所以它们被均匀分配给三个计算节点,并附带其所有入边。
相对的,对于高度数的节点 1,它的 4 条入边被均分给了各个计算节点。
这样做的依据也很简单,可以概括为“度数大的点数量稀少且很难保证其 replica 的数量,因此我们干脆优先保证数量众多的度数小的点不存在 replica”。
简单地说,hybrid-cut 可以被看成是 1D 和 2D 划分的混合(对度数小的点用 1D,大的用 2D)。
P.S. 随后他们还在 ApSys '14 上公开了一种针对于二分图的划分方法,同样的简单有效。详情可参考“Bipartite-oriented Distributed Graph Partitioning for Big Learning”。
4 下回预告
下一篇目前的打算是介绍一下利用磁盘进行单机图计算的框架,主要包括 GraphChi 和 X-Stream 这两个系统。
Click to read
May 06, 2016
0 引言
随着分布式数据库的普及,一致性模型(Consistency Model)这个原本只在系统领域研究人员这个小圈子中传播的概念的知名度也越来越高。
然而,由于这一概念相对来说本身就比较复杂,而且不同的小圈子(e.g., 单机多线程,分布式系统,数据库)使用的术语又总是有那么些微妙的差别,最终的结果就基本是一团浆糊。
就连向来备受信任的维基百科也不得不在其关于 Consistency Model 的页面上标注特别的声明,以提醒说 “This article may be confusing or unclear to readers”。
因此,作为我个人的一个总结,本文将列举据我所知最常见的几种一致性模型的定义以及它们之间的区别(总体来说本文的内容主要由这篇英文博客的翻译和一系列私货组成)。
若有什么不当之处望请通过邮件向我提出,我会尽快予以修正。
1 什么是一致性模型
由于传播途径的原因,一致性这个概念最常见的定义是“同一数据的多个副本之间是否保持一致”。
在描述上这个定义容易让人产生两个不必要的误解:
一是可能会有人误以为只有在不同机器上存在多个副本时才会产生一致性问题;
二则是它忽略了由于没能保证数据操作的原子性而导致的数据不一致(经典的银行转账的例子想必不用我特意来复述)。
这里我无意去细究这些文字上的问题,因此我打算用“顺序”这一更加明确的概念来进行重新的定义,即一致性模型规定的是“我们能够明确地区分哪些操作的先后顺序”。
形式化地来说,我们想象一个支持特定种类操作的数据结构,那么这个数据结构的一致性模型就定义了对其进行并发访问时各操作最终生效顺序上的约束。
如果你进行过多线程或者分布式的编程的话,想必你一定能够理解上文中提到的“最终生效”的顺序经常并不等价于各个操作的时间顺序(比如说在几乎同一时间对一个 Concurrent Queue 并发执行两次 Push 操作的话,其结果并不一定按照这两个 Push 操作的开始或结束时间存放)。
另外需要注意的是,这里我们不关心数据结构内部的状态,仅仅讨论由操作的返回值所观测到的结果。
在这一语境下我们能够定义得到的最简单的一致性模型为无一致(No Consistency),即不保证任何一致性。
它的意思是每一次操作的返回结果都是未定义的,可以返回任意的结果。
使得这一情况出现的最常见原因是未能够保证操作的原子性(thread-unsafe)导致了数据结构内部的不一致,不过这已经属于软件错误的范畴内了,因此本文不与进行进一步地讨论。
相对的,常见的一致性模型都至少保证 arranged correctly,即我们可以找到至少一个特定的顺序 $\mathcal{o}$,使得这些并发操作的结果与将它们依次按照 $\mathcal{o}$ 所规定的顺序在单线程上执行相同。
在这一条件下,一致性模型其实就是定义了 $\mathcal{o}$ 所能选择的一个范围。
换句话说,如果并发执行了 $N$ 个操作,那么理论上就有 $N!$ 种可能的顺序,而一致性模型就是定义了由这 $N!$ 种顺序构成的全集中的一个子集 $\mathcal{O}$,并规定 $\mathcal{o} \in \mathcal{O}$。
熟悉数据库系统的读者可能立即就会发现,上述定义中一致性的概念相对于所谓 ACID 特性中的 C 更加类似于 I 的定义。
这也就是为什么我在引言中会特意提到各领域间术语意义不一致的来由之一。
更进一步的,虽说在单机多线程和分布式环境下常说的一致性都是采用的上述的这个定义,它们常用的术语还是有些微妙的区别。
因此,本文随后将首先讨论单机多线程环境下常见的几种一致性模型,因为它们有着较为严格的形式化定义。
其它模型则会在最后分别进行讨论。
2 单机多线程环境下的一致性模型
2.1 强一致(Strong Consistency)
强一致模型有时也被称之为可线性化(Linearizability),是单机多线程环境下常见一致性模型中最强的一类(即 $|\mathcal{O}|$ 最小的一类)。
他要求任意两个在时间上不重合的操作(无论这两个操作是否在不同的线程中执行)都能够被区分顺序。
借用这篇博客中的图示来说明的话, 每一个操作都被表示为一条线段,不同的轨道表示不同的线程,而横轴为时间顺序。
如果这一数据结构是满足强一致的那么操作 x 对其的修改对于所有在 x 结束时间之后才开始的操作都是可见的。
相对的,如果另一个操作 y 的执行时间与 x 有重合(如图中红色的那些操作),那么 x 与 y 的生效顺序是任意的。

按照定义强一致模型是可组合的。也就是说如果一个操作由两个满足强一致的子操作组成,那么父操作也是强一致的。
强一致提供了一系列很好的特性,也非常的易于理解,但问题在于它基本很难得到高效的实现。
因此,研究人员就将其进一步的放松,从而得到了在单机多线程环境下实际上普遍存在的顺序一致性。
2.2 顺序一致(Sequential Consistency)
我们可以很容易地想到,强一致之所以难以高效实现的原因在于它对由不同线程执行的操作间的顺序都作出了限制,因此需要一个全局同步的时钟。
相对的,顺序一致模型(也被称之为可序列化)就只要求能够区分同一线程中各个操作的顺序。
用同上的图例的话,就会得到下图所示的结果。
从中我们可以看到,只要两个操作的执行线程是不同的,那么它们最终的生效顺序就是任意的。

虽然看上起顺序一致已经对约束进行了极大地放松,但事实上还是不够的,甚至可以说我们现在常用的各种编程语言其实都是不支持完整的顺序一致的。
这主要是因为现在的 CPU 和编译器会尝试对代码进行各种各样的优化,有时候它们可能会为了优化性能而把程序员在写程序时规定的代码执行顺序打乱,从而导致程序不满足顺序一致的结果。
举一个很简单的例子,假设 x 和 y 这两个变量的初始值都为 0,而两个线程分别执行以下的程序:
| Thread 1 |
Thread 2 |
| x := 1; |
y := 1; |
| res1 := y; |
res2 := x; |
在满足顺序一致的情况下,上述的程序最终是绝对不会出现 res1 和 res2 的值都等于 0 的情况(其他三种都是可能的)。
但为了得到更好的效率,编译器有可能在不清楚 x 和 y 是共享变量的情况下隐式的将 Thread 2 的两条指令的顺序颠倒(常见的原因包括向两条数据依赖的指令间插入一些其它指令以防指令流水被打断等)。
在这种情况下只要程序是按照 Thread 2 -> Thread 1 -> Thread 1 -> Thread 2 的顺序执行,就会产生 res1 和 res2 的值都等于 0 这种不满足顺序一致的结果。
因此,为了在效率和一致性之间进行 tradeoff,现有的编程语言(如 C++)一般只提供 “sequential consistency for data race free programs”。
也就是说,只有当所有的共享内存变量都有相应的同步原语进行保护(即没有 data race)时,程序的顺序一致才得到保证。
P.S. 顺序一致并不满足上面提到的可组合性,由多个顺序一致的操作组成的父操作并不一定满足顺序一致。
2.3 静态一致(Quiescent Consistency)
虽然顺序一致在实现效率上较之强一致优势非常明显,但其完全不对不同线程间操作进行限制的特性有时也会使得只支持顺序一致的数据结构变得难以使用。
因此 Maurice Herlihy 和 Nir Shavit 等人提出了静态一致的概念,它保证如果两个分属不同线程的操作间有一段完全空闲的时间,那么这两个操作的顺序是可以被区分的。
图形化的表示的话就是下面这种感觉:

需要注意的是,被称之为 Quiescent 的这一段时间是要求完全空闲的,即没有任何一个线程有执行操作。
得益于这个条件,静态一致同样是可组合的。
虽然看上去很奇怪,有很多的 Concurrent Data Structure 提供的就是静态一致的模型,具体的话可以参考这篇文章。
3 其它一致性模型
3.1 最终一致 (Eventual Consistency)
在分布式环境下,由于不同计算单元间进行通讯的开销远大于单机多线程的情况,即便是上述的简化版顺序一致依然是难以达成的。
因此,考虑到在很多实际的例子中用户其实并不要求他们的操作立即生效,研究人员就提出了最终一致的概念。
在定义上,最终一致只要求当两个操作间的间隔时间足够长时保证它们之间的顺序。
然而事实上这个定义并不比没有高出多少,因为其并不定义隔了多长就可以称之为“足够长”了。
简单地来说最终一致性可以算得上是一个下限,他基本上就是“为了 IOPS 我已经什么都不管了,总是最后总是会有效的,你也就别要求那么多了”的代名词。
3.2 严格一致 (Strict Consistency)
总体来说严格一致的定义和 2.1 中提到的强一致是很类似的,不过它只针对 read 和 write 这两个原子的操作。
其要求所有的 write 都立即有效,即所有发生在这个 write 的结束时间点之后的 read 都能读到这个 write 所写的值。
3.3 释放一致 (Release Consistency)
与严格一致类似,释放一致性也只是针对两个特殊的操作 acquire 和 release(可以类比于加锁和解锁)。
它要求所有所有对共享变量的修改操作都必须包含在一对 acquire 和 release 中。
在这一条件下,它就保证如果一个计算单元成功进行了 acquire,那么在这之前所有已经执行完 release 了的操作都是可见的。
(基本上类似于前面提到的 sequential consistency for data race free programs)。
Click to read